
So here are four main steps to follow when searching for freelancers:
1) Inspect. Before you consider searching for the right freelancer, have a clear vision of what the project is about.
2) Shortlist. Once you've examined each freelancer that is bidding, you can now think about making a short list.
3) Interview.
4) Hire.
1) Inspect. Before you consider searching for the right freelancer, have a clear vision of what the project is about.
2) Shortlist. Once you've examined each freelancer that is bidding, you can now think about making a short list.
3) Interview.
4) Hire.
Within the service page, you will see a 'Contact Seller' button at right side. We recommend contacting your seller before placing your order, especially if you have specific requirements.
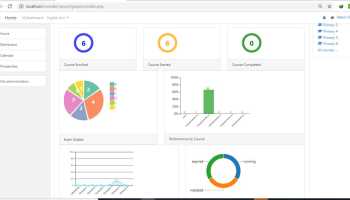
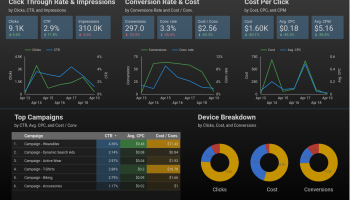
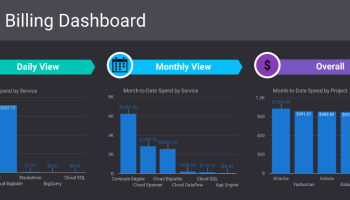
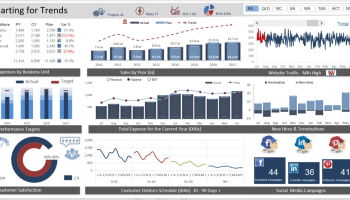
Freelance service is any fixed contract service. Designing, tax filing, software development with no full time commitment comes under freelance service.